구글 클라우드 Speech-To-Text(Google Cloud Speech-to-Text)는 음성(오디오)를 텍스트로 바꿔주는 머신러닝 기반의 변환 기술이다. 이 API를 이용하면 개발자가 오디오를 텍스트로 변환하여 다양한 분야에 응용할 수 있다.
120개 이상의 언어, 다양한 어휘를 인식하고 강력한 소음 필터링, 실시간 스트리밍 또는 사전 녹음된 오디오지원도 가능하다.
구글 클라우드 Speech-To-Text는 완전히 무료는 아니고 오디오 누적 재생시간 60분이상은 요금이 발생한다. 그리고 동기식 요청 시 오디오 길이는 1분으로 제한된다. 자세한 요금정책 및 한도는 다음 페이지를 참고하면된다. https://cloud.google.com/speech-to-text/pricing
또한 구글 클라우드 Speech-To-Text API를 이용하기 위해선 구글 클라우드 플랫폼에서 무료 평가판 신청을 해야하며, 무료 평가기간 이후 요금은 별도로 정산된다.
API는 다양한 언어를 위한 클라이언트 라이브러리 및 gRPC, REST방식으로 이용가능하며 몇가지 언어를 위한 예제 응용프로그램을 제공한다. https://cloud.google.com/speech-to-text/docs/samples
필자의 경우 HTTP REST API를 이용하여 Qt기반(C++)으로 테스트해 보았다.
API는 꽤 심플하다. 아래는 공식 문서에 나와있는 REST에 대한 내용의 일부이다.
Cloud Speech API
강력한 신경망 모델을 적용하여 오디오를 텍스트로 변환합니다.
Service: speech.googleapis.com
All URIs below are relative to https://speech.googleapis.com
This service provides the following discovery document:
REST Resource: v1.operations
| Methods | |
get |
GET /v1/operations/{name} Gets the latest state of a long-running operation.
|
| Methods | |
longrunningrecognize |
POST /v1/speech:longrunningrecognize Performs asynchronous speech recognition: receive results via the google.longrunning.Operations interface.
|
recognize |
POST /v1/speech:recognize Performs synchronous speech recognition: receive results after all audio has been sent and processed.
|
클라이언트 구현부분에서 recognize 또는 longrunningrecognize를 이용하면된다.
음성인식을 요청할때 HTTP 프로토콜의 body는 JSON포맷으로 작성되어야하며 아래 예제는 원격에 있는 오디오 uri 정보와 config 기본 내용을 포함한 JSON형식을 보여준다.
{
"config": {
"encoding":"FLAC",
"sampleRateHertz": 16000,
"languageCode": "en-US",
"enableWordTimeOffsets": false
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
최상의 결과를 얻으려면 오디오 소스를 무손실 인코딩 (FLAC 또는 LINEAR16)으로 해야하며 샘플링 속도를 16000Hz로 설정하여 전송해야한다. languageCode는 BCP-47 언어 태그로 language-region 형태로 한다.
오디오 소스를 직접 전송하는 경우 "uri" 대신 "content"를 사용하여 base64로 인코딩 된 문자열을 포함한다.
요청이 성공한 경우 응답 본문에는 다음과 같은 구조의 데이터가 포함된다. 음성 인식으로 반환되는 문자열 인코딩은 utf-8이다.
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.9833518
}
]
}
]
}
Qt기반(C++)으로 테스트 응용프로그램 작성
구현 할 응용프로그램에 대한 시퀀스는 대략 아래 그림과 같다. 사용자의 음성인식 요청을 recognize를 통해 동기로 처리한다.
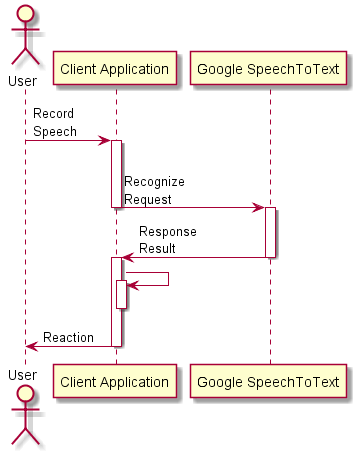
QNetworkAccessManager
QNetworkAccessManager 클래스를 사용하면 응용 프로그램에서 네트워크 요청을 보내고 응답을받을 수 있다.
QNetworkRequest
QNetworkAccessManager 객체를 통해 전송할 요청을 만든다.
QNetworkReply
요청에 대한 Response 데이터와 헤더를 사용할 수 있다.
아래는 위의 Qt 클래스들을 통해 구글음성인식을 요청하는 방법을 보여준다. <<your token>>에 접근 토큰과 json 형식으로 작성한 body를 QByteArray에 포함하여 post를 한다.
QNetworkAccessManager networkmanager;
QUrl url("https://speech.googleapis.com/v1/speech:recognize");
QNetworkRequest request(url);
request.setRawHeader("Content-Type", "application/json");
request.setRawHeader("Authorization", "Bearer <<your token>>");
QByteArray body;
QNetworkReply *reply = networkmanager.post(request, body);
Qml로도 자바스크립트 객체를 통해 HTTP요청을 할 수 있는데 아래는 그 예제 소스코드이다.
import QtQuick 2.11
import QtQuick.Window 2.11
import QtQuick.Controls 1.4
Window {
id: idWindow
visible: true
width: 320
height: 240
title: qsTr("Hello Makersweb")
Button{
text: "recognize"
onClicked: request()
anchors.centerIn: parent
}
function writeBody(){
var obj = {
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
// "content": "ZkxhQwAAACIQABAAAAEhABUoA+gA8AAAcTOFakWoVSA3I0P2YDJO7klfA .....";
},
"config": {
"encoding": "FLAC",
"languageCode": "en-US",
"sampleRateHertz": 16000
}
};
return JSON.stringify(obj);
}
function request(){
var xhr = new XMLHttpRequest;
var url = "https://speech.googleapis.com/v1/speech:recognize"
xhr.onreadystatechange = function(){
if(xhr.readyState === XMLHttpRequest.HEADERS_RECEIVED){
}else if(xhr.readyState === XMLHttpRequest.DONE){
if(xhr.responseText){
var object = JSON.parse(xhr.responseText.toString())
print(JSON.stringify(object, null, 2))
}
}
}
xhr.open("POST", url)
xhr.setRequestHeader("Content-Type", "application/json")
xhr.setRequestHeader("Authorization", "Bearer <<your token>>")
xhr.send(writeBody())
}
}
테스트 응용프로그램의 GUI는 Qml로 구현.
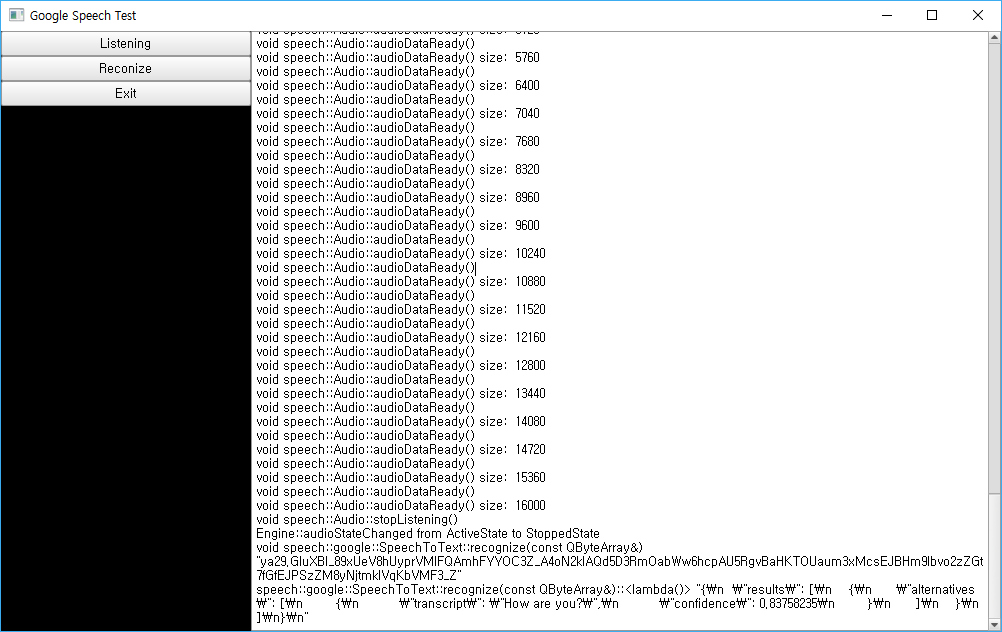
Qt Network 를 이용한 예제는 다음 저장소에 있다.
https://gitlab.com/pjk1985/speech.git
 Qt SQL을 이용한 가벼운 데이터베이스 다루기
Qt SQL을 이용한 가벼운 데이터베이스 다루기











