
Elasticsearch, Kibana, Beats, Logstash(ELK Stack이라고도 함) 등으로 구성하여 데이터 및 로그 수집, 검색, 분석, 시각화 할 수 있다.
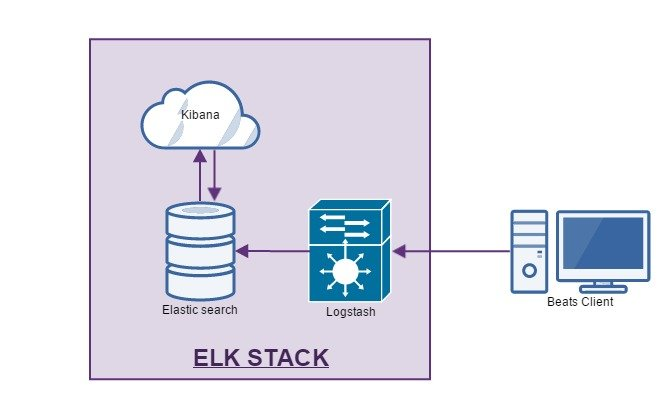
다음 이미지는 ELK스택에 대한 대략적인 구조를 보여준다.
Logstash
로그 항목을 받아 필터링한 후 ElasticSearch DB로 전달한다.
기본적인 Logstash는 ElasticSearch로 data shipper 역할을 했다. 어플리케이션에서 생산되는 log 등에 대해서 분석 및 수집 도구인 ElasticSearch로 전송의 역할도 담당했다. 이후 더 경량의 data shipper인 filebeat가 나왔다.
로그를 생성하는 서버들에 Filebeat를 설치하고, 로그를 집계할 서버에 ELK를 설치한다. 기본적으로 무겁고 (JAVA 런타임이 필요)많은 시스템 리소스 비용을 요구한다.
Filebeat의 경우 Logstash에 비해 Resource(CPU와 RAM)를 적게 소모한다고 주장하고 있지만 이마저도 소형 임베디드 장치에서는 무거워 보인다.
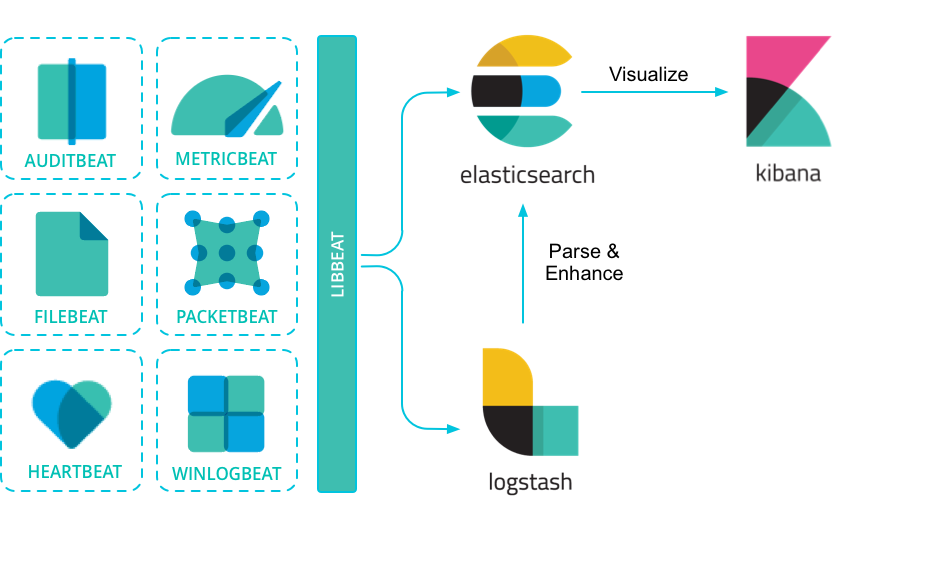
Filebeat의 libbeat는 게시자를 구현하므로 사용자 정의/비즈니스 로직만 구현하면 된다. 하지만 libbeat의 문제점은 Go에서만 사용할 수 있다는 것이다. 많은 소형 임베디드 및 IoT 기기가 Go를 실행할 수 없기 때문에 이부분은 매우 유감스러운 일이다. (다행히도 C++ 언어를 위한 포트로 비공식적인 구현이 있긴하다. 공식적으로 제공할 계획이 없는 것처럼 보인다.)
libbeat이 버퍼링을 처리한다는 점은 중요하다. 버퍼링은 클라이언트가 몇 시간 또는 며칠 동안이라도 네트워크 연결이 끊기면 데이터를 로컬에 저장하고 연결이 복구되면 버퍼링된 모든 데이터를 서버로 전송한다는 것을 의미한다. 이렇게 하면 서버 데이터베이스에 중단된 데이터가 없게 된다. 또한 최적의 데이터 샘플링 속도를 선택해야 하므로 데이터베이스가 단시간에 커지지 않는다. 버퍼링은 매우 중요한 기능이며, 직접 구현하는 경우도 있긴하다.
ELK를 사용하는 장점은 인프라를 설정하기가 편하고, 프로젝트가 오픈 소스이며 활성화된 커뮤니티도 있다는 것이다. 문제는 여전히 소형 임베디드 장치에 적합하느냐 인데 libbeat API가 Go에서만 사용할 수 있어 베어메탈 IoT 기기에 사용할 수 없고, Elastic Stack의 도구가 복잡하고 부풀어 있어 의존성 문제를 완전히 통제 및 관리하기 어려운 리스크가 분명있다. (기본적으로 의존성이 크다) 이것은 문제가 발생할 때 직접 디버깅하기 어려울 수 있다는 점을 의미한다. 물론, 수많은 기능과 기능을 제공하므로 복잡할 것은 당연할 것이며 실제로도 사용할 가능성이 더 높은 유용한 기능이 많다. 비즈니스 요구사항에 따라 적합성을 따져봐야 할 것이다.
ELK 의 좋은 대안으로 Manticore Search 를 고려해볼 수 있다. 로그 분석을 위해 Elasticsearch보다 29배 더 빠르며 빅데이터의 경우 Elasticsearch보다 4배 더 빠르고 C++로 구축된 Manticore Search는 빠르게 시작되고 최소한의 RAM을 사용하며 낮은 수준의 최적화로 인상적인 성능을 제공한다.
