
[폴링(Polling)]
호스트와 입/출력 하드웨어 사이의 프로토콜은 복잡하지만 기본적인 핸드셰이킹(hand shaking) 개념은 간단하다. 제어기는 상태 레지스터의 busy 비트를 통해 자신의 상태를 나타낸다. 제어기는 바쁠 때는 busy 비트를 1로 설정하고 다음 명령을 받아들일 준비가 되어 있을 경우에는 busy 비트가 0으로 변경한다.
호스트는 다음과 같은 방법으로 핸드셰이킹을 통해 제어기와 협력하면서 포트를 통해 출력을 쓴다. 호스트가 반복적으로 (소거될 때까지) busy 비트를 검사한다.
호스트가 명령 레지스터에 쓰기 비트(write bit)를 설정하고 출력(data out)레지스터에 출력할 바이트를 쓴다.
1. 호스트가 명령어 준비 완료 비트(command ready bit)를 설정한다.
2. (입/출력 하드웨어) 제어기가 명령어 준비 완료 비트가 설정된 것을 알아 차렸을 때 자신의 busy 비트를 설정한다.
3. (입/출력 하드웨어) 제어기는 명령어 레지스터를 읽고 write 명령어임을 알게 된다. 출력 레지스터를 읽어 해당 바이트를 가져와 해당 하드웨어 장치로 출력한다.
4. (입/출력 하드웨어) 제어기는 명령어 준비 완료 비트를 소거하고 입/출력이 끝났음을 알리기 위해 busy 비트를 소거한다.
이 루프는 매 바이트마다 반복되며 1단계에서 호스트는 폴링(polling)을 하게 된다.
[인터럽트(Interrupt)]
입/출력 장치가 CPU에게 자신의 상태 변화를 통보하는 하드웨어 기법을 인터럽트(interrupt)라 한다. CPU하드웨어는 인터럽트 요청 라인(interrupt request line)이라고 불리는 선을 하나 갖는데 CPU는 매 명령어를 끝내고 다음 명령어를 수행하기 전에 인터럽트 요청 라인을 검사한다.
1. 입/출력 하드웨어 제어기가 이 요청 라인에 신호를 보낸다.
2. CPU가 각종 레지스터 값과 상태 정보를 저장한 다음 메모리 상의 인터럽트 핸들러 루틴으로 이동 한다.
3. 인터럽트 핸들러는 인터럽트의 발생 원인을 조사하고 필요한 작업을 수행 한 후 CPU를 인터럽트 이전 상태로 되딜리는 명령을 수행 한다.
4. 핸들러는 입/출력 장치를 서비스함으로써 이 인터럽트를 처리해 준다.
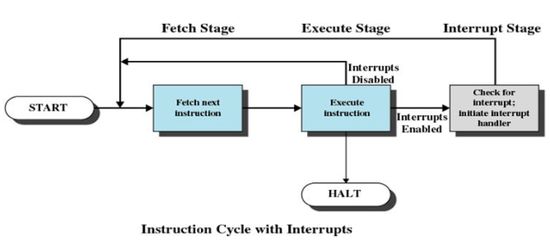
대부분의 CPU 들은 두 종류의 인터럽트 요청 라인을 가진다.
l 마스크 불가 인터럽트(nonmaskable interrupt) : 회복 불가능한 메모리 에러와 같은 이벤트를 위해 사용
l 마스크 가능 인터럽트(maskable interrupt) : 필요 시 인터럽트 기능을 잠시 중단시켜 놓을 수 있는 기능으로 장치 제어기가 서비스를 요청하기 위해 사용한다. 인터럽트 되어서는 안 되는 주요 명령 시퀀스를 수행하기 전에 CPU가 끌 수 있다.
인터럽트 기법은 보통 주소라고 하는 하나의 작은 정수를 받아 들이는데 이 정수는 특정 인터럽트 핸들링 루틴을 선택하기 위해 사용되며 대부분의 구조에서 이 주소는 인터럽트 벡터라고 불리는 테이블의 오프셋으로 사용된다.
컴퓨터는 인터럽트 벡터 내에 있는 주소들보다 더 많은 수의 장치를 갖고 있다. 이러한 문제를 해결하구 위해 인터럽트 사슬(chaining) 기술을 사용한다. 인터럽트 사슬화에는 인터럽트 벡터의 각 원소들이 여러 인터럽트 핸들러들로 이루어진 리스트의 헤더를 가리키고 있다. 인터럽트가 발생하면 해당 핸들러가 찾아질 때까지 리스트 상의 핸들러들을 하나씩 검사하게 된다.
인터럽트 기법은 인터럽트 우선순위 수준(interrupt priority level)의 구현을 가능하게 한다. 이 기법은 CPU가 모든 낮은 우선순위 인터럽트를 일일이 마스크 오프(mask off)시키지 않더라도 자동적으로 높은 우선순위 인터럽트가 낮은 순위 인터럽트의 실행을 선점(preempt) 할 수 있게 한다.
[DMA (Direct Memory Access)]
CPU가 상태 비트를 반복적으로 검사하면서 1 바이트씩 옮기는 입/출력 방식을 PIO(Programmed I/O)라고 한다. 많은 컴퓨터들은 CPU의 PIO 작업 중 일부를 DMA(Direct Memory Access) 제어기라고 불리는 특수 처리기에 위임함으로써 CPU의 일을 줄여 준다.
DMA 전송을 시작시키기 위해서 호스트는 메모리에 DMA 명령 블록을 쓴다. 이 블록에는 전송할 자료가 있는 곳의 포인터와 전송할 장소에 대한 포인터, 그리고 전송될 바이트 수를 기록해 놓는다. 그리고 CPU는 이 DMA명령 블록의 주소를 DMA에게 알려주고 자신은 다른 일을 한다. DMA는 CPU의 도움 없이도 자신이 직접 버스를 통해 DMA 명령 블록을 접근하여 입/출력을 수행하게 된다.
DMA 제어기와 장치 제어기(Device controller)간의 핸드셰이킹은 DMA-request와 DMA-acknowledge라고 불리는 두 개의 선을 통해 수행 된다.
1. 장치 제어기는 전송할 자료가 생기면 DMA-request 선에 신호를 보낸다.
2. 이 신호를 받으면 DMA 제어기가 메모리버스를 얻어 거기에 원하는 주소를 올려놓고 DMA-acknowledge 선에 신호를 보낸다.
3. 장치 제어기가 DMA-acnkowledge 신호를 받으면 제어기는 한 워드를 메모리로 전송하고 DMA-request 신호를 제거 한다.
4. 전송이 완전히 끝나면 DMA 제어기는 CPU에게 인터럽트를 건다.
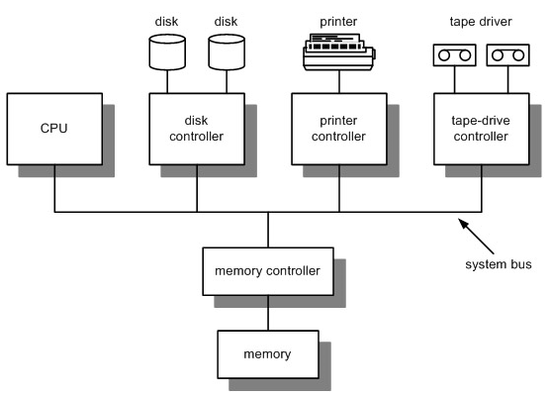
DMA가 메모리 버스를 점유중이면 비록 CPU는 주 캐시와 보조 캐시에 있는 자료는 접근할 수 있지만 일시적으로 주 메모리에 있는 자료는 접근하지 못한다. 이러한 사이클 스틸링(cycle stealing)은 CPU의 속도를 저하시키지만 입/출력 작업을 DMA로 넘기는 것은 전체적으로 시스템 성능을 향상 시킨다.
DMA를 사용할 때 물리적 주소를 사용하지만 DVMA(직접 가상 메모리 접근, direct virtual memory access)을 사용하기도 한다. DVMA를 사용하면 CPU나 메모리의 개입이 없어도 가상 주소로 두 개의 메모리 매핑(memory mapped) 장치간에 자료를 전송 할 수가 있게 된다.
[참고자료]
Operating System Concepts / 홍릉과학출판사
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 15 |
USB 핀아웃
| pjk | 2014.10.11 | 13296 |
| 14 |
시리얼 인터페이스 커넥터를 위한 핀아웃
| pjk | 2014.10.10 | 9687 |
| 13 |
STM32와 CAN(Controller Area Network) Loop Back
| makersweb | 2017.01.23 | 11072 |
| 12 |
윈도우10에서 Prolific USB to Serial 드라이버 인식문제
| makersweb | 2016.01.24 | 29263 |
| 11 |
AVRISP mkII 펌웨어 업그레이드
| makersweb | 2015.07.22 | 12500 |
| 10 |
이클립스에서 IAR프로젝트 사용방법
| makersweb | 2015.07.09 | 14410 |
| 9 |
JFlashARM으로 MCU에 bin(바이너리)다운로드
| makersweb | 2015.06.07 | 11496 |
| 8 |
AVR(AT90USB162)을 USB to Serial 로 이용하기
| makersweb | 2015.02.14 | 10777 |
| 7 | 실시간 운영 체제 또는 RTOS(Real Time Operating System) | pjk | 2014.12.02 | 10863 |
| » |
폴링(Polling), 인터럽트(Interrupt), DMA(Direct Memory Access)
| pjk | 2014.10.24 | 11552 |
| 5 |
부트로더의 start.S 분석
| makersweb | 2014.03.23 | 8760 |
| 4 | 임베디드 시스템 개발 환경 선택 | makersweb | 2014.03.05 | 8556 |
| 3 |
GNU C 레퍼런스 메뉴얼 - 부록 D
| makersweb | 2014.02.28 | 5 |
| 2 | printk() | makersweb | 2014.02.27 | 9129 |
| 1 | [Uboot 명령어 및 환경 변수 요약]U-Boot에 Command 및 Parameter에 대한 설명 | pjk | 2014.01.09 | 16091 |
